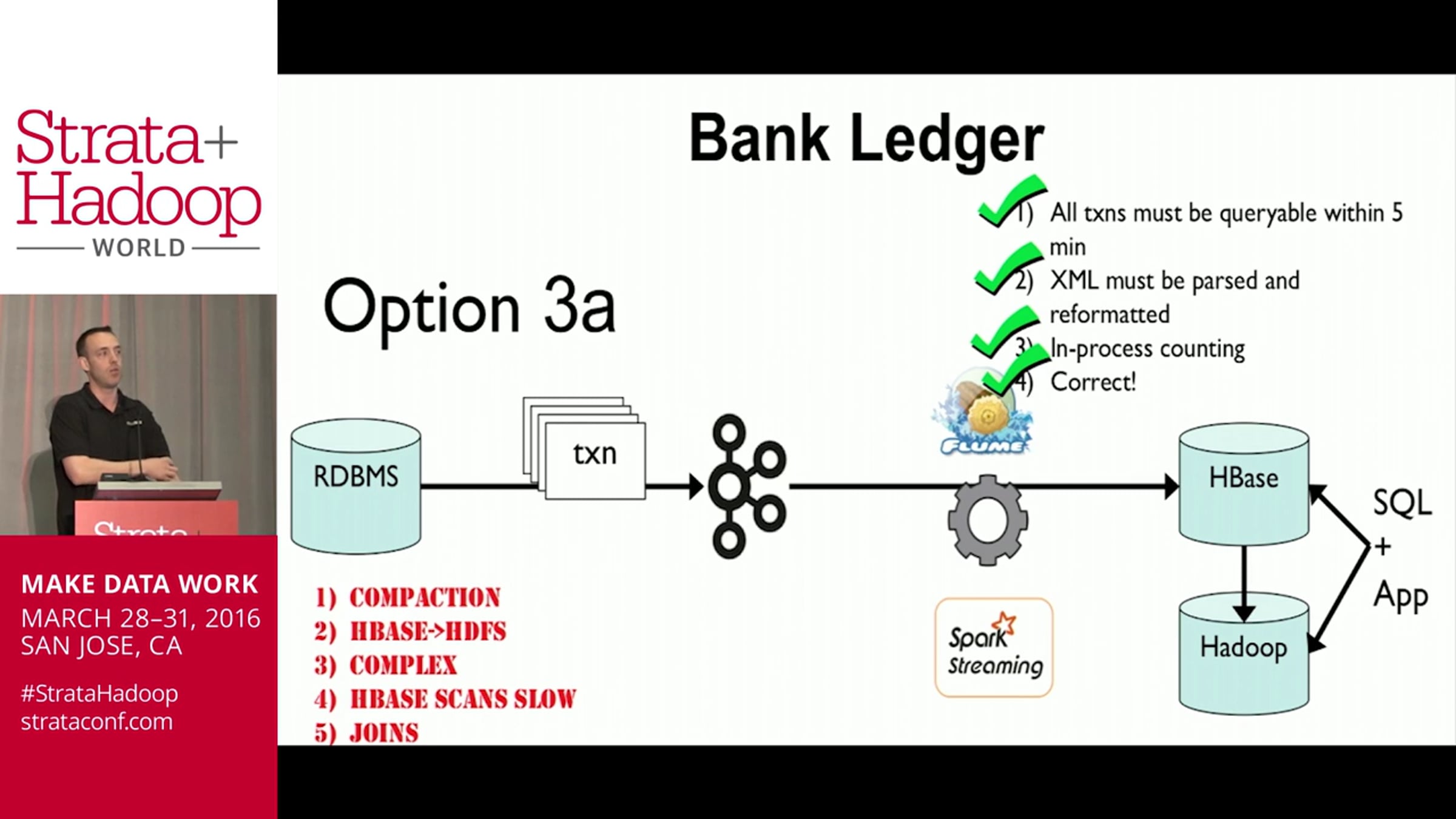
Fast data made easy with Apache Kafka and Apache Kudu (incubating)

Historically, use cases such as time series and mutable-profile datasets have been possible but difficult to achieve efficiently using traditional HDFS storage engines. These solutions might involve complex ingestion paths, deep understanding of file types, and compaction strategies. With the introduction of Kudu, many of these difficulties are eliminated. At the same time, interest in streaming solutions and low-latency analytics has surged with the growing popularity of tools like Apache Kafka. (From Strata + Hadoop World San Jose 2016)
Get started for free
24/7 customer support
Our customer support team is available to help 24/7. Enterprise members also receive dedicated account managers and a guaranteed uptime SLA.
© 2026 Vimeo.com, Inc. All rights reserved.
TermsPrivacyYour Privacy ChoicesU.S State PrivacyCopyrightCookies